Обучение с подкреплением на Python: Пример не из «качалки»
Постановка задачи
Обучение с подкреплением молодая и бурно растущая дисциплина. Это обстоятельство привело к тому, что информации об этом мало на английском и почти нет на русском языке. Особенно, если дело касается объектно-ориентированного подхода, и практических задач не из арсенала Open Gym. Стало интересно, как решать задачи RL в других средах.
Представляю вам результат простой задачи, которая как я надеюсь, убережет вас от части шишек встречающихся на этом интересном пути.
Предположим задачу, в которой нано робот с антибиотиком должен подобраться к скоплению патогенных бактерий для их уничтожения.
Загрузим Reinforsment Learning от Keras и библиотеку для анимации.
Среда
Для обучения с подкреплением требуется среда и агент.
Средой в нашем случае будет мигрирующие в тканях патогены. Их движение соответствует роевому поведению.
Роевое поведение описано моделью Вичека (1995 г.).С помощью этой системы можно имитировать скопления бактерий, поведение стаи птиц или косяка рыб, а также увидеть, как из простых правил появляются само упорядоченные движения.
Возьмем описание модели из статьи Создание собственной симуляции активной материи на Python. И перепишем ее используя объектно-ориентированный подход. Предполагается, что вы уже знакомы с ООП для Python.
Описанный класс послужит нам для описания состояния среды state. Не путайте observation и state. Наблюдаемые данные observation, это только то, что наблюдает агент. Состоянием state считается вся среда: описание всех наших бактерий.
Для правильной работы в автоматическом режиме требуется через атрибуты класса action_space и observation_space описать допустимые значения action агента и представление среды observation.
Их надо наследовать от класса rl.Space. Для action_space требуется переписать методы:
В атрибуте shape классов мы будем хранить форму значений
Для того чтобы сделать среду нам надо создать класс наследуя ее из базового класса среды rl.Env предоставляемой керас. Это абстрактный класс, в соответствии с задуманной средой необходимо описать его методы:
В классе среды мы должны описать состояние state, наблюдение observation, награду reward.
В observation подадим 5 переменных:
Количество «захваченных» бактерий внутри радиуса R
Средний угол направления бактерий внутри R
Угол направления на центр бактерий внутри R
Угол направления на центр бактерий внутри круга R-1.5R
Текущий угол направления нано робота
Действием,- будет угол движения нано робота. Все переменные нормализуем делением на Pi.
На этом этапе, давайте определим параметры среды и проиграем случайные эпизоды.
 Проигрыш эпизодов
Проигрыш эпизодов
Просмотр эпизодов даст понимание с каким разнообразием ситуаций успевает столкнуться наш робот. В зависимости от этого, регулируем: количество бактерий; размер площадки; скорость и количество эпох.
Вы можете это сделать в ноутбуке Google Collab.
Агент и обучение
Среда определена. Остается создать агента.
Для решения задачи используем метод Deep Deterministic Policy Gradient (DDPG), его можно рассматривать как DQN для непрерывных пространств действий. Мы попеременно обучаем 2 сети Актера(производит действие action) и Критика(оценивает вознаграждение reward).
Для тренировки используется keras-rl класс DDPGAgent. Он берет на себя всю техническую реализацию, а нам остается написать несколько строчек кода и получить результат. ООП великая сила!
Результат
Давайте посмотрим на действия обученного нано робота. Изменим для наглядности параметры среды
Результат обучения
Выводы
При планировании актера, если существует непрерывный допустимый диапазон органов управления, последний нейрон лучше зажать активациями sigmoid(0,1) или tanh(-1,+1) вместо linear. Затем в step() среды развернуть до требуемого диапазона.
Отдельно надо отметить, что набор подаваемых данных должен быть адекватен задаче. Не получится научить агента вождению не показывая дороги. В нашем случае пришлось показать бактерии ситуацию чуть за пределами радиуса R. Без этого наш робот просто тащился за последней бактерией в рое, боясь быть наказанным и не понимая как получить награду.
Через тернии лежит путь к звездам. Буду рад, если кому-то помог разобраться в этой интереснейшей теме.
Введение в обучение с подкреплением для начинающих
Обучение с подкреплением в – это способ машинного обучения, при котором система обучается, взаимодействуя с некоторой средой.
В последние годы мы наблюдаем прогресс в исследованиях в данной области. Например DeepMind, Deep Q learning в 2014, победа чемпиона мира в Go с помощью алгоритма AlphaGo в 2016, OpenAl и PPO в 2017
В этой статье мы сфокусируемся на изучении различных архитектур, которые активно используются вместе с обучением с подкреплением в наши дни для решения различного рода проблем, а именно Q-learning, Deep Q-learning, Policy Gradients, Actor Critic и PPO.
Из этой статьи, вы узнаете:
Очень важно освоить все эти элементы, прежде чем погружаться в реализацию системы глубинного обучения с подкреплением.
Идея обучения с подкреплением заключается в том, что система будет учиться в среде, взаимодействовать с ней и получать вознаграждение за выполнение действий. 
Представьте, что вы ребенок в гостиной. Вы увидели камин и захотели подойти к нему. 
Тут тепло, вы хорошо себя чувствуете. Вы понимаете, что огонь – это хорошо. 
Но потом вы пытаетесь дотронуться до огня и обжигаете руку. Только что вы осознали, что огонь – это хорошо, но только тогда, когда находитесь на достаточном расстоянии, потому что он производит тепло. Если подойти слишком близко к нему, вы обожжетесь.
Вот как люди учатся через взаимодействие. Обучение с подкреплением – это просто вычислительный подход к обучению на основе действий.
Как выглядит обучение с подкреплением

Давайте в качестве примера представим, что система учится играть в Super Mario Bros. Процесс обучения с подкреплением может быть смоделирован как цикл, который работает следующим образом:
Этот цикл ОП выводит последовательность состояний, действий и вознаграждений.
Цель системы – максимизировать ожидаемое вознаграждение.
Главная идея гипотезы вознаграждения
Почему целью системы является максимизация ожидаемого вознаграждения?
Обучение с подкреплением основано на идее гипотезы вознаграждения. Все цели можно описать максимизацией ожидаемого вознаграждения.
Вознаграждение на каждом временном шаге (t) может быть записано как:
Что эквивалентно: 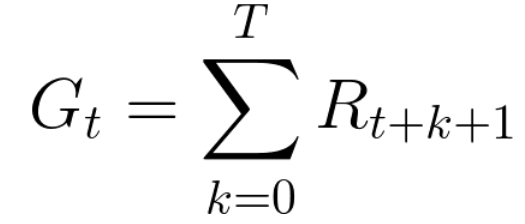
Однако на самом деле мы не можем просто добавить такие награды. Награды, которые приходят раньше (в начале игры), более вероятны, так как они более предсказуемы, чем будущие вознаграждения.

Допустим, ваш герой – это маленькая мышь, а противник – кошка. Цель игры состоит в том, чтобы съесть максимальное количество сыра, прежде чем быть съеденным кошкой.
Как мы можем видеть на изображении, скорее всего мышь будет есть сыр рядом с собой, нежели сыр, расположенный ближе к кошке (т.к. чем ближе мы к кошке, тем она опаснее).
Как следствие, ценность награды рядом с кошкой, даже если она больше обычного (больше сыра), будет снижена. Мы не уверены, что сможем его съесть.
Перерасчет награды, мы делаем таким способом:
Мы определяем ставку дисконтирования gamma. Она должна быть в пределах от 0 до 1.
Ожидаемые вознаграждения можно рассчитать по формуле: 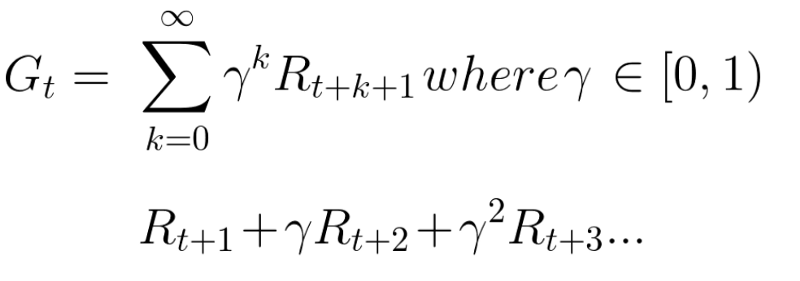
Другими словами, каждая награда будет уценена с помощью gamma к показателю времени (t). По мере того, как шаг времени увеличивается, кошка становится ближе к нам, поэтому будущее вознаграждение все менее и менее вероятно.
Эпизодические или непрерывные задачи
У нас может быть два типа задач: эпизодические и непрерывные.
Эпизодические задачи
В этом случае у нас есть начальная и конечная точка. Это создает эпизод: список состояний, действий, наград и будущих состояний.
Например в Super Mario Bros, эпизод начинается с запуска нового Марио и заканчивается, когда вы убиты или достигли конца уровня.
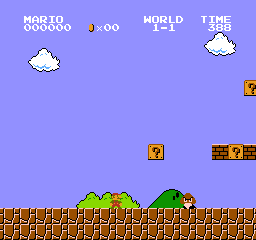
Непрерывные задачи
Это задачи, которые продолжаются вечно. В этом случае система должна научиться выбирать оптимальные действия и одновременно взаимодействовать со средой.
Как пример можно привести систему, которая автоматически торгует акциями. Для этой задачи нет начальной точки и состояния терминала. Что касается нашей задачи, то герой будет бежать, пока мы не решим остановить его. 
Борьба методов: Монте-Карло против Временной разницы
Существует два основных метода обучения:
Монте-Карло
Когда эпизод заканчивается, система смотрит на накопленное вознаграждение, чтобы понять насколько хорошо он выполнил свою задачу. В методе Монте-Карло награды получают только в конце игры.
Затем, мы начинаем новую игру с новыми знаниями. С каждым разом система проходит этот уровень все лучше и лучше.
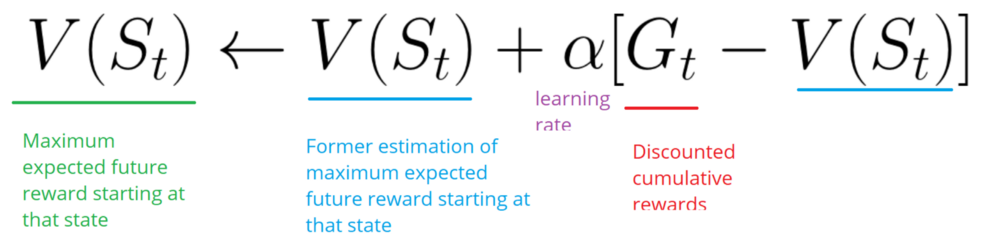
Возьмем эту картинку как пример:
Временная разница: обучение на каждом временном шаге
Этот метод не будет ждать конца эпизода, чтобы обновить максимально возможное вознаграждение. Он будет обновлять V в зависимости от полученного опыта.
Метод вызывает TD (0) или One step TD (обновление функции value после любого отдельного шага). 
Он будет только ждать следующего временного шага, чтобы обновить значения. В момент времени t+1 обновляются все значения, а именно вознаграждение меняется на Rt+1, а текущую оценка на V(St+1).
Разведка или эксплуатация?
Прежде чем рассматривать различные стратегии решения проблем обучения с подкреплением, мы должны охватить еще одну очень важную тему: компромисс между разведкой и эксплуатацией.
Помните, что цель нашей системы заключается в максимизации ожидаемого совокупного вознаграждения. Однако мы можем попасть в ловушку.
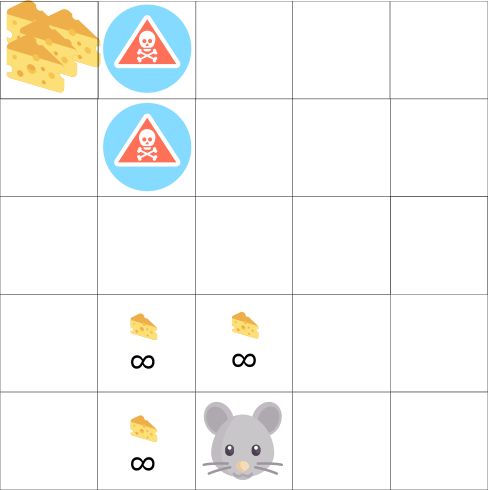
В этой игре, наша мышь может иметь бесконечное количество маленьких кусков сыра (+1). Однако на вершине лабиринта есть гигантский кусок сыра (+1000).
Но, если мы сосредоточимся только на вознаграждении, наша система никогда не достигнет того самого большого куска сыра. Вместо этого она будет использовать только ближайший источник вознаграждений, даже если этот источник мал (эксплуатация).
Но если наша система проведет небольшое исследование, она найдет большую награду.
Это то, что мы называем компромиссом между разведкой и эксплуатацией. Мы должны определить правило, которое поможет справиться с этим компромиссом.
Три подхода к обучению с подкреплением
Теперь, когда мы определили основные элементы обучения с подкреплением, давайте перейдем к трем подходам для решения проблем, связанных с этим обучением.
На основе значений
В обучении с подкреплением на основе значений целью является оптимизация функции V(s).
Функция value – это функция, которая сообщает нам максимальное ожидаемое вознаграждение, которое получит система.
Значение каждой позиции – это общая сумма вознаграждения, которую система может накопить в будущем, начиная с этой позиции.
Система будет использовать эту функцию значений для выбора состояния на каждом шаге. Она принимает состояние с наибольшим значением.

На основе политики
В обучении с подкреплением на основе политики мы хотим напрямую оптимизировать функцию политики π (s) без использования функции значения.
Политика – это то, что определяет поведение системы в данный момент времени.
Это позволяет нам сопоставить каждую позицию с наилучшим действием.
Существует два типа политики:
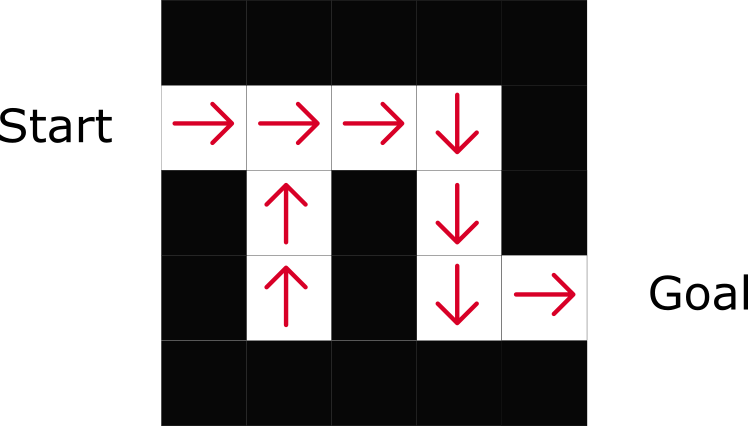
Как можно заметить, политика прямо указывает на лучшие действия для каждого шага.
На основе модели
В подходе на основании модели мы моделируем среду. Это означает, что мы создаем модель поведения среды.
Проблема каждой среды заключается в том, что понадобятся различные представления данной модели. Вот почему мы особо не будем раскрывать эту тему.
В этой статье было довольно много информации. Убедитесь, что действительно поняли весь материал, прежде чем продолжить изучение. Важно освоить эти элементы перед тем как начать самую интересную часть: создание ИИ, который играет в видеоигры.
Обучение с подкреплением на нейронных сетях. Теория
Так мне указали, что для задачи классификации — нейронные сети (обучение с учителем), генетические алгоритмы (обучение без учителя) — задача кластеризации, а еще есть обучение с подкреплением (Q-обучение) — как задача агента, который бродит и что-то делает. И вот такими шаблонами многие и судят.
Попробуем разобраться, что дает применение нейронных сетей, как некоторые заявляют, к задаче которую они не могут решить — а именно к обучению с подкреплением.
И заодно проанализируем диссертацию Бурцев М.С., «Исследование новых типов самоорганизации и возникновения поведенческих стратегий», в которой не больше не меньше красиво сделано именно применение простеньких нейронных сетей в задаче обучения с подкреплением.
Теория
В генетических алгоритмах и в методах для обучения с подкреплением (напр., Q-обучение) есть одна существенная проблема — нужно задавать функцию пригодности. Причем она задается явно формулой. Иногда она появляется косвенно — тогда кажется, что этой функции явно нет (это мы проследим далее, на анализе диссертации Бурцева М.С.). И все «чудеса» агентного поведения происходят только от этой формулы.
Но что такое формула? — Функция. Или что тоже самое отображение входов на выходы. А что делает нейронная сеть/перцептрон? Именно это он и делает — обучается отображать входы на выходы.
Возьмем утрированный теоретический пример. Агент — это какой-то организм, которому хочется выжить. Для этого ему надо есть. Он есть два вида животных — ну пусть зайцев и мышей. Соответственно у него есть два входных параметра — количество килограмм, которые содержит съеденная зайчатина и мышатина :). Он (организм) хочет оценивать на сколько он сыт. Тогда в зависимости от того, на сколько он сыт он может бегать с большей или меньшей скоростью и желанием. Но это уже другая задача, а мы остановимся на оценке сытости.
Нам ничего не известно как оценивать сытость, кроме килограмм того и другого. Поэтому первая естественная оценка — это научиться складывать килограммы. Т.е. мы вводим простую функцию пригодности c= a+b. Замечательно, но имея такую жесткую функцию оценки мы не можем корректировать свое поведение.
Поэтому применяется нейронная сеть. Её вначале обучают складывать эти два числа. После обучения нейронная сеть умеет безошибочно складывать. Агент использует выход нейронной сети и понимает на сколько он сыт.
Но далее происходит несчастье — он оценил, что он сыт на 7 баллов = съев 4 кило зайчатины и 3 мышатины. И бегал думая, что наелся, так что чуть не переусердствовал и не помер. Оказалось, что 4 кило зайчатины и 3 мышатины — это не тоже самое, что 7 кило зайчатины. Мышатина не дает такой же сытости, и складывать на самом деле нужно как 4 + 3 = 6. Вот этот сделанный им вывод он и вкидывает как точную данность в нейронную сеть. Она переобучается, и её функция пригодности уже не простое сложение, и приобретает совершенно другой вид. Таким образом, имея нейронную сеть мы может корректировать функцию пригодности, чего не можем делать в других алгоритмах.
Вы можете сказать, что в других алгоритмах надо было просто брать не функцию сложения. Но какую? У вас нет ни соответствующих параметров, ни принципов на которых вы бы вывели нужную закономерность. Вы просто не смогли бы формализовать такую задачу, т.к. не смогли бы понять пространство состояний.
Практика на примере диссертации Бурцева М.С.
Какая у него модельная среда:
Популяция P агентов A, находящихся в одномерной клеточной среде, замкнутой в виде кольца. В клетках с некоторой вероятностью появляется ресурс, необходимый агентам для совершения действий. В одной клетке может находиться только один агент. Агент-потомок может появиться только в результате скрещивания двух агентов-родителей. У агента 9 входов
1,2,3 — 1 если в данной клетке поля зрения (слева, рядом, справа) есть ресурс, 0 в противном случае;
4, 5 — 1 если в клетке слева/справа есть агент, 0 в противном случае;
6,7 — мотивация к скрещиванию Mr соседа слева/справа;
8 — собственная мотивация к поиску пищи
9 — собственная мотивация к скрещиванию
Мотивация к скрещиванию и поиску пищи определяется через отношение двух коэффициентов выбранных экспериментатором — r0 — значения внутреннего ресурса для насыщения и r1 — для скрещивания.
Существует 6 действий: скрещиваться с соседом справа, скрещиваться с соседом слева, прыгать, двигаться на одну клетку вправо, двигаться на одну клетку влево, потреблять ресурс, отдыхать
Была изначально настроенная ИНС, конечно её сетью назвать сложно — без внутреннего слоя, но пусть. Она имела различные коэффициенты, как входы связанны с действиями (выходами). Далее применялся генетический алгоритм, который настраивал коэффициенты нейронной сети, и отбраковал организм с плохим поведением.
По сути генетические алгоритмы тут не сильно и нужны. Можно аналогично случайно перебирать разные стратегии поведения и фиксировать пригодные, корректируя нейронную сеть.
На самом деле, проблема с Q-learning и генетическими алгоритмами заключается в том, что новое поведение ищется случайно. А случайность это равновероятный поиск на всем пространстве возможных состояний. Т.е. в этом нет целенаправленного поиска. А если пространство возможных состояний велико, то элементарные стратегии так никогда и не будут найдены.
Поэтому вообще-то нужно не случайно перебирать разные стратегии, а целенаправленно (но об этом нужно уже говорить в следующей статье после понимания первых штрихов :)).
Я пробежался быстро, т.к. нам важны лишь выводы, а не детали. Но Вам возможно нужно почитать об этом самим подробнее.
В итоге функция пригодности агента представлена нейронной сетью. Как в изложенной теории выше, так и у Бурцева в диссертации.
Но отличаем её от функции пригодности среды. Она тут косвенно задана через коэффициенты r0 и r1. Причем эта функция пригодности среды — экспериментатору известна. Поэтому нет ни какой фантастики, когда Бурцев обнаруживает как функция пригодности агента начинает приближаться к функции пригодности среды.
В статье Проблема «двух и более учителей». Первые штрихи у нас ситуация — хуже. Функцию пригодности среды не знает даже экспериментатор, точнее вид этой функции. В этом то и проблема, она ни как косвенно не определяется. Да, известно лишь конечная функция пригодности — максимум денег, но внутри себя она содержит подфункцию, которая не известна. Функции пригодности агента, надо стремится к этой подфункции — а она не может быть вычислена.
Надеюсь теперь будет немного более понятно.
Введение в различные алгоритмы обучения с подкреплением (Q-Learning, SARSA, DQN, DDPG)
(Q-learning, SARSA, DQN, DDPG)
Обучение с подкреплением (RL далее ОП) относится к разновидности метода машинного обучения, при котором агент получает отложенное вознаграждение на следующем временном шаге, чтобы оценить свое предыдущее действие. Он в основном использовался в играх (например, Atari, Mario), с производительностью на уровне или даже превосходящей людей. В последнее время, когда алгоритм развивается в комбинации с нейронными сетями, он способен решать более сложные задачи.
В силу того, что существует большое количество алгоритмов ОП, не представляется возможным сравнить их все между собой. Поэтому в этой статье будут кратко рассмотрены лишь некоторые, хорошо известные алгоритмы.
1. Обучение с подкреплением
Типичное ОП состоит из двух компонентов, Агента и Окружения.
Окружение – это среда или объект, на который воздействует Агент (например игра), в то время как Агент представляет собой алгоритм ОП. Процесс начинается с того, что Окружение отправляет свое начальное состояние (state = s) Агенту, который затем, на основании своих значений, предпринимает действие (action = a ) в ответ на это состояние. После чего Окружение отправляет Агенту новое состояние (state’ = s’) и награду (reward = r) Агент обновит свои знания наградой, возвращенной окружением, за последнее действие и цикл повторится. Цикл повторяется до тех пор, пока Окружение не отправит признак конца эпизода.
Большинство алгоритмов ОП следуют этому шаблону. В следящем параграфе я кратко расскажу о некоторых терминах, используемых в ОП, чтобы облегчить наше обсуждение в следующем разделе.
Определения:
1. Action (A, a): все возможные команды, которые агент может передать в Окружение (среду)
2. State (S,s): текущее состояние возвращаемое Окружением
3. Rewrd (R,r): мгновенная награда возвращаемое Окружением, как оценка последнего действия
5. Value (V) или Estimate (E) : ожидаемая итоговая (награда) со скидкой, в отличии от мгновенной награды R, является функцией политики Eπ(s) и определяется, как ожидаемая итоговая награда Политики в текущем состоянии s. (Встречается в литературе два варианта Value – значение, Estimate – оценка, что в контексте предпочтительней использовать E – оценка. Прим. переводчика)
6. Q-value (Q): оценка Q аналогична оценки V, за исключением того, что она принимает дополнительный параметр a (текущее действие). Qπ(s, a) является итоговой оценкой политики π от состояния s и действия a
 * MCTS (Монте-Карло тайм степ модель), on-policy (алгоритм, где Агент включен в политику, т.е. обучается на основе действий, производных от текущей политики), off-policy (Агент обучается на основе действий, полученных от другой политики
* MCTS (Монте-Карло тайм степ модель), on-policy (алгоритм, где Агент включен в политику, т.е. обучается на основе действий, производных от текущей политики), off-policy (Агент обучается на основе действий, полученных от другой политики
Безмодельные алгоритмы против алгоритмов базирующихся на моделях
С другой стороны, безмодельные алгоритмы опираются на метод проб и ошибок для обновления своих знаний. В результате им не требуется место для хранения комбинаций состояние / действие и их оценок.
2. Разбор Алгоритмов
2.1. Q-learning
Q-learning это не связанный с политикой без модельный алгоритм ОП, основанный на хорошо известном уравнении Беллмана:
Мы можем переписать это уравнение в форме Q-value:
Оптимальное значение Q, обозначенное как Q*, может быть выражено как:
Цель состоит в том, чтобы максимизировать Q-значение. Прежде чем углубиться в метод оптимизации Q-value, я хотел бы обсудить два метода обновления значений, которые тесно связаны с Q-learning.
Итерация политики
Итерация политики представляет собой цикл между оценкой политики и ее улучшением.
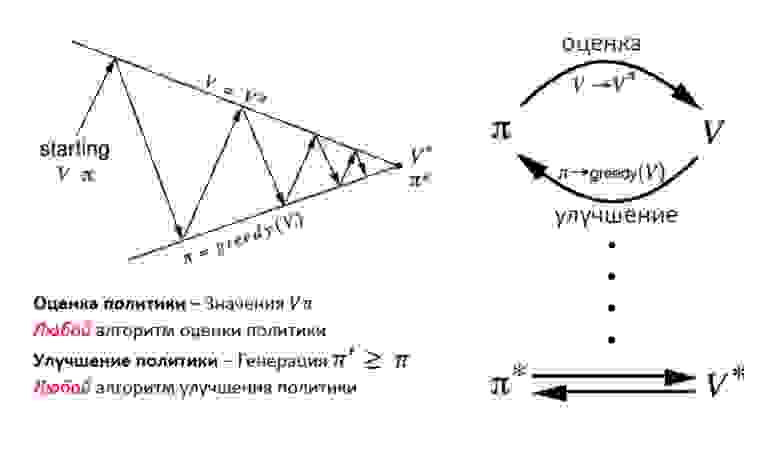
Оценка политики оценивает значения функции V с помощью «жадной политики» полученной в результате последнего улучшения политики. С другой стороны, улучшение политики обновляет политику, генерирующую действия (action – a), что максимизирует значения V для каждого состояния (окружения). Уравнения обновления основаны на уравнении Беллмана. Итерации продолжаются до схождения.
Итерация Оценок (V)
Итерация оценок содержит только один компонент, который обновляет функцию оценки значений V, на основе Оптимального уравнения Беллмана.
После того, как итерация сходится, оптимальная политика напрямую выводится путем применения функции максимального аргумента для всех состояний.
Обратите внимание, что эти два метода требуют знания вероятности перехода p, что указывает на то, что это алгоритм на основе модели. Однако, как я упоминал ранее, алгоритм, основанный на модели, страдает проблемой масштабируемости. Так как же Q-Learning решает эту проблему?
Здесь a (альфа) скорость обучения (т.е. как быстро мы приближаемся к цели) Идея Q-learning во многом основана на итерациях оценок (v). Однако уравнение обновления заменяется приведенной выше формулой. В результате нам больше не нужно думать о вероятности перехода (p).
Обратите внимание, что следующее действие a’ выбирается для максимизации Q-значения следующих состояний вместо того, чтобы следовать текущей политике. В результате Q-learning относится к категории вне политики (off-Policy).
2.2. State-Action-Reward-State-Action (SARSA)
SARSA очень напоминает Q-learning. Ключевое отличие SARSA от Q-learning заключается в том, что это алгоритм с политикой (on-policy). Это означает, что SARSA оценивает значения Q на основе действий, выполняемых текущей политикой, а не жадной политикой.
Уравнения ниже показывают разницу между рассчетом значений Q
Где действие at+1 – это действие выполняемое в следующем состоянии st+1 в соответствии с текущей политикой.
Они выглядят в основном одинаково, за исключением того, что в Q- learning мы обновляем нашу Q-функцию, предполагая, что мы предпринимаем действие a, которое максимизирует нашу Q-функцию в следующем состоянии Q (st + 1, a).
В SARSA мы используем ту же политику (например, epsilon-greedy), которая сгенерировала предыдущее действие a, чтобы сгенерировать следующее действие, a + 1, которое мы запускаем через нашу Q-функцию для обновлений, Q (st + 1, at+1). (Вот почему алгоритм получил название SARSA, State-Action-Reward-State-Action).
В Q-learning у нас нет ограничений на то, как выбирается следующее действие a, у нас есть только оптимистичный взгляд на то, что все последующие выборы действий a в каждом состоянии s будут оптимальными, поэтому мы выбираем действие a, чтобы максимизировать оценку Q (st+1, a). Это означает, что с помощью Q-learning мы можем генерировать данные политикой с любым поведением (обученной, необученной, случайной и даже плохой), при наличии достаточной выборки мы получим оптимальные значения Q
2.3. Deep Q Network (DQN)
аваВ 2013 году DeepMind применил DQN к игре Atari, как показано на рисунке выше. Входными данными является необработанное изображение текущей игровой ситуации. Оно проходит через несколько сверхточных слоев, а затем через полно связный слой. Результатом является Q-значение для каждого действия, которое может предпринять агент.
Вопрос сводится к следующему: как мы обучаем сеть?
Ответ заключается в том, что мы обучаем сеть на основе уравнения обновления Q-learning. Напомним, что целевое значение Q для Q-learning:
φ эквивалентно состоянию s, в то время как θ обозначает параметры в нейронной сети, что не входит в область нашего обсуждения. Таким образом, функция потерь для сети определяется как квадрат ошибки между целевым значением Q и выходным значением Q из сети.
Еще два метода также важны для обучения DQN:
1. Воспроизведение опыта: поскольку обучающие батчи в типичной настройке ОП(RL) сильно коррелированы и менее эффективны для обработки данных, это приведет к более сложной конвергенции для сети. Одним из способов решения проблемы выборки батчей является воспроизведение опыта. По сути, батчи переходов сохраняются, а затем случайным образом выбираются из «пула переходов» для обновления знаний.
2. Отдельная целевая сеть: целевая сеть Q имеет ту же структуру, что и сеть, которая оценивает значение. Каждый шаг C, в соответствии с приведенным выше псевдокодом, целевая сеть принимает значения основной сети. Таким образом, колебания становятся менее сильными, что приводит к более стабильным тренировкам.
2.4. Deep Deterministic Policy Gradient (DDPG)
Хотя DQN добилась огромных успехов в задачах более высокой размерности, таких как игра Atari, пространство действий по-прежнему остается дискретным. Однако для многих задач, представляющих интерес, особенно для задач физического контроля, пространство действий непрерывно. Если вы слишком дискретизируете пространство действия, вы получите слишком большой объем. Например, предположим, что степень свободной случайной системы равна 10. Для каждой степени вы делите пространство на 4 части. У вас будет 4¹⁰ = 1048576 действий. Чрезвычайно сложно получить схождение для такого большого пространства действий, а это еще не предел.
Критик используется для оценки функции политики Актора в соответствии с ошибкой временной разницы (TD)
Здесь u обозначает политику Актора. Знакомо? Да! Это похоже на уравнение обновления Q-learning. TD-learning – это способ научиться предсказывать значение в зависимости от будущих значений данного состояния. Q-learning это особый тип TD-learning для получения Q значений
DDPG также заимствует идеи воспроизведения опыта и отдельной целевой сети от DQN. Другой проблемой для DDPG является то, что он редко выполняет поиск действий. Решением для этого является добавление шума в пространство параметров или пространство действий (action).
Слева шум добавлен к действиям, справа к параметрам
Утверждается, что добавление шума в пространство параметров лучше, чем в пространство действий, согласно статье написанной на OpenAI.